 Научные и курсовые работы |
Главная
Исторические личности
Военная кафедра
Ботаника и сельское хозяйство
Бухгалтерский учет и аудит
Валютные отношения
Ветеринария
География
Геодезия
Геология
Геополитика
Государство и право
Гражданское право и процесс
Естествознанию
Журналистика
Зарубежная литература
Зоология
Инвестиции
Информатика
История техники
Кибернетика
Коммуникация и связь
Косметология
Кредитование
Криминалистика
Криминология
Кулинария
Культурология
Логика
Логистика
Маркетинг
Наука и техника Карта сайта
Реферат: Выборочные исследования в эконометрике
Реферат: Выборочные исследования в эконометрике
РЕФЕРАТ
По эконометрике
Выборочные исследования
Термин "выборочные исследования" применяют, когда невозможно изучить все единицы представляющей интерес совокупности. Приходится знакомиться с частью совокупности - с выборкой, а затем с помощью эконометрических методов и моделей переносить выводы с выборки на всю совокупность. В качестве примера рассмотрим выборочные исследования предпочтений потребителей, которые часто проводят специалисты по маркетингу.
Построение выборочной функции спроса
Функция спроса часто встречается в экономических учебниках, но при этом обычно не рассказывается, как она получена. Между тем оценить ее по эмпирическим данным не так уж трудно. Мы часто выясняем ожидаемый спрос с помощью следующего простого приема - спрашиваем потенциальных потребителей: "Какую максимальную цену Вы заплатили бы за такой-то товар?" Пусть для определенности речь идет о конкретном учебном пособии по менеджменту. В одном из экспериментов выборка состояла из 20 опрошенных. Они назвали следующие максимально допустимые для них цены (в рублях по состоянию на сентябрь 1998 г.):
40, 25, 30, 50, 35, 20, 50, 32, 15, 40, 20, 40, 45, 30, 50, 25, 35, 20, 35, 40.
Первым делом названные величины надо упорядочить в порядке возрастания. Результаты представлены в табл.1. В первом столбце - номера различных численных значений (в порядке возрастания), названных потребителями. Во втором столбце приведены сами значения цены, названные ими. В третьем столбце указано, сколько раз названо то или иное значение.
Табл.1. Эмпирическая оценка функции спроса и ее использование
| № п/п (i) | Цена pi | Ni |
Спрос D(p i) |
Прибыль (p-10)D(р) |
Прибыль (p-15)D(р) |
Прибыль (p-25)D(р) |
|
1 |
15 |
1 |
20 |
100 |
0 |
- |
|
2 |
20 |
3 |
19 |
190 |
95 |
- |
|
3 |
25 |
2 |
16 |
240 |
160 |
0 |
|
4 |
30 |
2 |
14 |
280 |
210 |
70 |
|
5 |
32 |
1 |
12 |
264 |
204 |
84 |
|
6 |
35 |
3 |
11 |
275 |
220 |
110 |
|
7 |
40 |
4 |
8 |
240 |
200 |
120 |
|
8 |
45 |
1 |
4 |
140 |
120 |
80 |
|
9 |
50 |
3 |
3 |
120 |
105 |
75 |
Таким образом, 20 потребителей назвали 9 конкретных значений цены (максимально допустимых, или приемлемых для них значений), каждое из значений, как видно из третьего столбца, названо от 1 до 4 раз. Теперь легко построить выборочную функцию спроса в зависимости от цены. Она будет представлена в четвертом столбце, который заполним снизу вверх. Если мы будем предлагать товар по цене свыше 50 руб., то его не купит никто из опрошенных. При цене 50 руб. появляются 3 покупателя. Записываем 3 в четвертый столбец в девятую строку. А если цену понизить до 45? Тогда товар купят четверо – тот единственный, для кого максимально возможная цена - 45, и те трое, кто был согласен на большую цену 50 руб. Таким образом, легко заполнить столбец 4, действуя по правилу: значение в клетке четвертого столбца равно сумме значений в находящейся слева клетке третьего столбца и в лежащей снизу клетке четвертого столбца. Например, за 30 руб. купят товар 14 человек, а за 20 руб. - 19.
Зависимость спроса от цены - это зависимость четвертого столбца от второго. Табл.1 дает нам девять точек такой зависимости. Зависимость можно представить на рисунке, в координатах «спрос – цена». Если абсцисса - это спрос, а ордината - цена, то девять точек на кривой спроса, перечисленные в порядке возрастания абсциссы, имеют вид:
(3; 50), (4; 45), (8; 40), (11; 35), (12; 32), (14; 30), (16; 25), (19; 20), (20; 15).
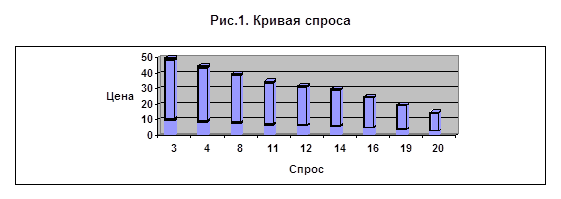
Эти девять точек можно
использовать для построения кривой спроса каким-либо графическим или расчетным
способом, например, методом наименьших квадратов (см. ниже главу 5). Кривая
спроса, как и должно быть согласно учебникам экономической теории, убывает,
имея направления от левого верхнего угла чертежа к правому. Однако заметны
отклонения от гладкого вида функции, связанные, в частности, с естественным
пристрастием потребителей к круглым числам. Заметьте, все опрошенные, кроме
одного, назвали числа, кратные 5 руб.
Данные табл.1 могут быть использованы для выбора цены продавцом-монополистом (или действующем на рынке монополистической конкуренции). Пусть расходы на изготовление единицы товара равны 10 руб. (например, оптовая цена книги - 10 руб.). По какой цене ее продавать на том рынке, функцию спроса для которого мы только что нашли? Для ответа на этот вопрос вычислим суммарную прибыль, т.е. произведение прибыли на одном экземпляре (p-10) на число проданных (точнее, запрошенных) экземпляров D(p). Результаты приведены в пятом столбце табл.1. Максимальная прибыль, равная 280 руб., достигается при цене 30 руб. за экземпляр. При этом из 20 потенциальных покупателей окажутся в состоянии заплатить за книгу 14, т.е. 70% .
Если же удельные издержки производства, приходящиеся на одну книгу (или оптовая цена), повысятся до 15 руб., то данные столбца 6 табл.1 показывают, что максимальная прибыль, равная 220 руб. (она, разумеется, меньше, чем в предыдущем случае), достигается при более высокой цене - 35 руб. Эта цена доступна 11 потенциальным покупателям, т.е. 55% от всех возможных покупателей. При дальнейшем повышении издержек, скажем, до 25 руб., как вытекает из данных столбца 7 табл.1, максимальная прибыль, равная 120 руб., достигается при цене 40 руб. за единицу товара, что доступно 8 лицам, т.е. 40% покупателей. Отметьте, что при повышении оптовой цены на 10 руб. оказалось выгодным увеличить розничную лишь на 5, поскольку более резкое повышение привело бы к такому сокращению спроса, которое перекрыло бы эффект от повышения удельной прибыли (т.е. прибыли, приходящейся на одну проданную книгу).
Представляет интерес анализ оптимального объема выпуска при различных значениях удельных издержек (табл.2).
Табл.2. Прибыль при различных значениях издержек
| № п/п (i) | Цена pi |
Спрос D(p i) |
Прибыль (p-5)D(р) |
Прибыль (p-20)D(р) |
Прибыль (p-30)D(р) |
Прибыль (p-35)D(р) |
Прибыль (p-40)D(р) |
|
1 |
15 |
20 |
200 |
- |
- |
- |
- |
|
2 |
20 |
19 |
285 |
0 |
- |
- |
- |
|
3 |
25 |
16 |
320 |
80 |
- |
- |
- |
|
4 |
30 |
14 |
350 * |
140 |
0 |
- |
- |
|
5 |
32 |
12 |
324 |
144 |
24 |
- |
- |
|
6 |
35 |
11 |
330 |
165 * |
55 |
0 |
- |
|
7 |
40 |
8 |
280 |
160 |
80 * |
40 |
0 |
|
8 |
45 |
4 |
160 |
100 |
60 |
40 |
20 |
|
9 |
50 |
3 |
135 |
90 |
60 |
45 * |
30 * |
В табл.2 звездочками указаны максимальные значения прибыли при том или ином значении издержек, не включенном в табл.1. Для легкости обозрения результаты об оптимальных объемах выпуска и соответствующих ценах из табл. 1 и 2 приведены в табл.3.
Табл.3. Зависимость оптимального выпуска и цены от издержек
|
Издержки |
5 |
10 |
15 |
20 |
25 |
30 |
35 |
40 |
|
Оптимальный выпуск |
14 |
14 |
11 |
11 |
8 |
8 |
3 |
3 |
|
Цена |
30 |
30 |
35 |
35 |
40 |
40 |
50 |
50 |
Как видно из табл.3, с ростом издержек оптимальный выпуск падает, а цена растет. При этом изменение издержек на 5 единиц может вызывать, а может и не вызывать повышения цены. В этом проявляется микроструктура функции спроса – небольшое повышение цены может привести к тому, что значительные группы покупателей откажутся от покупок, и прибыль упадет.
Этот эффект напоминает известное в экономической теории разделение налогового бремени между производителем и потребителем. Неверно говорить, что производитель перекладывает издержки или, конкретно, налоги, на потребителя, повышая цену на их величину, поскольку при этом сокращается спрос (и выпуск), а потому и прибыль производителя.
Дальнейшее ясно - если оптовая цена будет повышаться, то и дающая максимальную прибыль розничная цена также будет повышаться, и все меньшая доля покупателей сможет приобрести товар. Крайняя точка - оптовая цена, равная 45 руб. Тогда только трое (15 %) купят товар за 50 руб., а прибыль продавца составит только 15 руб. Наглядно видно, что повышение издержек производства приводит к ориентации производителя на наиболее богатые слои населения, но и повышение цен (до оптимального для монополиста-производителя уровня) не приводит к повышению прибыли, напротив, она снижается, и при этом большинство потенциальных потребителей не в состоянии купить товар. Таково влияние инфляции издержек на экономическую жизнь. (Об инфляции мы подробнее поговорим позже.)
Отметим, что рыночные структуры не в состоянии обеспечить всех желающих – это просто не выгодно. Так, из 20 опрошенных лишь 14, т.е. 70%, могут рассчитывать на покупку, даже при минимальных издержках и ценах. Если общество желает чем-либо обеспечить всех граждан, оно должно раздавать это благо бесплатно, как это делается, например, с учебниками в школах.
Маркетинговые опросы потребителей
Потенциального покупателя интересует не только цена, но и качество товара, красота упаковки (например, для подарочных наборов конфет) и многое другое. Хочешь узнать, чего желает потребитель - спроси его. Эта простая мысль объясняет популярность маркетинговых опросов.
Бесспорно, что основная цель производственной и торговой деятельности - удовлетворение потребностей людей. Как получить представление об этих потребностях? Очевидно, необходимо опросить потребителей. В американском учебнике по рекламному делу [1] подробно рассматриваются различные методы опроса потребителей и обработки результатов с помощью методов эконометрики. Расскажем о результатах опроса потребителей растворимого кофе. Исследование проведено Институтом высоких статистических технологий и эконометрики по заказу АОЗТ "Д-2" в апреле 1994 г. в Москве.
Сбор данных. Обсудим постановку задачи. Заказчика интересуют предпочтения как продавцов кофе (розничных и мелкооптовых), так и непосредственно потребителей. В результате совместного обсуждения было признано целесообразным использовать для опроса и тех, и других одну и ту же анкету из 14 основных и 4 социально-демографических вопросов с добавлением двух вопросов специально для продавцов. Анкета была разработана совместно представителями заказчика и исполнителя и утверждена заказчиком. В табл.4 приведен несколько сокращенный вариант этой анкеты.
Табл.4. Анкета для потребителей растворимого кофе
_____________________________________________________________
Дорогой потребитель растворимого кофе,
Институт высоких статистических технологий и эконометрики просит Вас ответить на несколько простых вопросов о том, какой кофе Вы любите. Ваши ответы позволят составить объективное представление о вкусах российских любителей кофе и будут способствовать повышению качества этого товара на российском рынке.
1.Часто ли Вы пьете растворимый кофе: иногда, каждый день 1 чашку, 2-3 чашки, больше, чем 3 чашки.
(Здесь и далее подчеркните нужное.)
2. Что Вы цените в кофе: вкус, аромат, крепость, цвет, отсутствие вредных для здоровья веществ, что-либо еще (сообщите нам, что именно).
3. Как часто покупаете кофе: по мере надобности или по возможности?
4. Любите ли Вы бразильский растворимый кофе? Да, нет, не знаю.
5. Какой объем упаковки Вы предпочитаете: в пакетиках, маленькая банка, средняя банка, большая банка, обязательно стеклянная банка, все равно.
6. Где покупаете растворимый кофе: в ларьках, в продуктовых магазинах, в специализированных отделах и магазинах, все равно, где купить, где-либо еще (опишите, пожалуйста).
7. Были ли случаи, когда купленный Вами кофе оказывался низкого качества? Да, нет.
8. Согласны ли Вы, что за высокое и гарантированное качество продукта можно и заплатить несколько дороже? Да, нет.
9. Какой кофе Вы предпочтете купить: банка неизвестного качества за 2000 руб. или продукт того же веса, безопасность которого гарантирована Минздравом России, за 2500 руб.? Первый, второй.
10. Считаете ли Вы нужным, чтобы производитель принял меры для того, чтобы вредные для здоровья вещества, в частности, ионы тяжелых металлов, не проникали из материала упаковки непосредственно в растворимый кофе? Да, нет.
Институт высоких статистических технологий и эконометрики предполагает сравнить потребительские предпочтения различных категорий россиян. Поэтому просим ответить еще на несколько вопросов.
11. Пол: женский, мужской.
12. Возраст: до 20, 20-30, 30-50, более 50.
13. Род занятий: учащийся, работающий, пенсионер, инженер, врач, преподаватель, служащий, менеджер, предприниматель, научный работник, рабочий, др. (пожалуйста, расшифруйте).
14. Вся Ваша семья любит растворимый кофе или же Вы - единственный любитель этого восхитительного напитка современного человека? Вся семья, я один (одна).
15. Согласились бы Вы и в дальнейшем участвовать в опросах потребителей относительно качества различных пищевых продуктов (чай, джем и др.). Если "да", то сообщите свой адрес, телефон, имя и отчество.
Спасибо за Ваше содействие работе по повышению качества продуктов на российском рынке!
Выбор метода опроса. Широко применяются процедуры опроса, когда респонденты (так социологи и маркетологи называют тех, от кого получают информацию, т.е. опрашиваемых) самостоятельно заполняют анкеты (розданные им или полученные по почте), а также личные и телефонные интервью. Из этих процедур нами было выбрано личное интервью по следующим причинам.
Возврат почтовых анкет сравнительно невелик (в данном случае можно было ожидать не более 5-10%), оттянут по времени и искажает структуру совокупности потребителей (наиболее динамичные люди вряд ли найдут время для ответа на подобную анкету). Кроме того, есть проблемы с почтовой связью (постоянное изменение тарифов затрудняет возмещение респондентам почтовых расходов и др.).
Самостоятельное заполнение анкеты, как показали специально проведенные эксперименты, не позволяет получить полные ответы на поставленные вопросы (респондент утомляется или отвлекается, отказывается отвечать на часть вопросов, иногда не понимает их или отвечает не по существу). Некоторые категории респондентов, например, продавцы в киосках, отказываются заполнять анкеты, но готовы устно ответить на вопросы.
Телефонный опрос искажает совокупность потребителей, поскольку наиболее активных индивидуумов трудно застать дома и уговорить ответить на вопросы анкеты. Репрезентативность нарушается также и потому, что на один номер телефона может приходиться различное количество продавцов и потребителей растворимого кофе, а некоторые из них не имеют телефонов вообще. Анкета достаточно длинна, и разговор по домашнему и тем более служебному телефону респондента может быть прекращен досрочно по его инициативе. Иногородних продавцов и потребителей растворимого кофе, приехавших в Москву, по телефону опросить практически невозможно.
Метод личного интервью лишен перечисленных недостатков. Соответствующим образом подготовленный интервьюер, получив согласие на интервью, удерживает внимание собеседника на анкете, добивается получения ответов на все её вопросы, контролируя при этом соответствие ответов реальной позиции респондента. Ясно, что успех интервьюирования зависит от личных качеств и подготовки интервьюера. Однако расходы на получение одной анкеты при использовании этого метода больше, чем для других рассмотренных методов.
Формулировки вопросов. В маркетинговых и социологических опросах используют три типа вопросов - закрытые, открытые и полузакрытые, они же полуоткрытые. При ответе на закрытые вопросы респондент может выбирать лишь из сформулированных составителями анкеты вариантов ответа. В качестве ответа на открытые вопросы респондента просят изложить свое мнение в свободной форме. Полузакрытые, они же полуоткрытые вопросы занимают промежуточное положение - кроме перечисленных в анкете вариантов, респондент может добавить свои соображения.
В социологических публикациях продолжается дискуссия по поводу "мягких" и "жестких" форм сбора данных, т.е. фактически о том, какого типа вопросы более целесообразно использовать - открытые или закрытые (см., например, статью директора Института социологии РАН В.А. Ядова [2]). Преимущество открытых вопросов состоит в том, что респондент может свободно высказать свое мнение так, как сочтет нужным. Их недостаток - в сложности сопоставления мнений различных респондентов. Для такого сопоставления и получения сводных характеристик организаторы опроса вынуждены сами шифровать ответы на открытые вопросы, применяя разработанную ими схему шифровки. Преимущество закрытых вопросов в том и состоит, что такую шифровку проводит сам респондент. Однако при этом организаторы опроса уподобляются древнегреческому мифическому персонажу Прокрусту. Как известно, Прокруст приглашал путников заночевать у него. Укладывал их на кровать. Если путник был маленького роста, он вытягивал его ноги так, чтобы они доставали до конца кровати. Если же путник оказывался высоким и ноги его торчали - он обрубал их так, чтобы достигнуть стандарта: "рост" путника должен равняться длине кровати. Так и организаторы опроса, применяя закрытые вопросы, заставляют респондента "вытягивать" или "обрубать" свое мнение, чтобы выразить его с помощью приведенных в формулировке вопроса возможных ответов.
Ясно, что для обработки данных по группам и сравнения групп между собой нужны формализованные данные, и фактически речь может идти лишь о том, кто - респондент или маркетолог (социолог, психолог и др.) - будет шифровать ответы. В проекте "Потребители растворимого кофе" практически для всех вопросов варианты ответов можно перечислить заранее, т.е. можно широко использовать закрытые вопросы. В отличие от опросов с вопросами типа: "Одобряете ли Вы идущие в России реформы?", в которых естественно просить респондента расшифровать, что он понимает под "реформами" (открытый вопрос). Поэтому в используемой в описываемом проекте анкете использовались в основном закрытые и полузакрытые вопросы. Как показали результаты обработки, этот подход оказался правильным - лишь в небольшом числе анкет оказались вписаны свои варианты ответов. Вместе с тем демонстрировалось уважение к мнению респондента, не выдвигалось требование обязательного выбора из заданного множества ответов - респондент мог добавить свое, но редко пользовался этой возможностью (не более чем в 5% случаев).
В последнем вопросе анкеты респонденту предлагалось стать постоянным участником опросов о качестве товаров народного потребления. Ряд респондентов откликнулся на это предложение, в результате стало возможным развертывание постоянной сети "экспертов по качеству", подобной аналогичным в США.
Обоснование объема выборки и проведение опроса. Математико-статистические вероятностные модели выборочных маркетинговых и социологических исследований часто опираются на предположение о том, что выборку можно рассматривать как "случайную выборки из конечной совокупности" (см. терминологическое приложение). Типа той, когда из списков избирателей с помощью датчика случайных чисел отбирается необходимое число номеров для формирования жюри присяжных заседателей. В рассматриваемом проекте нельзя обеспечить формирование подобной выборки - не существует реестра потребителей растворимого кофе. Однако в этом и нет необходимости. Поскольку гипергеометрическое распределение хорошо приближается биномиальным, если объем выборки по крайней мере в 10 раз меньше объема всей совокупности (в рассматриваемом случае это так), то правомерно использование биномиальной модели, согласно которой мнение респондента (ответы на вопросы анкеты) рассматривается как случайный вектор, а все такие вектора независимы между собой. Другими словами, можно использовать модель простой случайной выборки. Таким образом, позиция в давней дискуссии в среде специалистов, изучающих поведение человека (маркетологов, социологов, психологов, политологов и др.) о том, есть ли случайность в поведении отдельно взятого человека или же случайность проявляется лишь в отборе выборки из генеральной совокупности, практически не влияет на алгоритмы обработки данных.
В биномиальной модели выборки оценивание характеристик происходит тем точнее, чем объем выборки больше. Часто спрашивают: "Какой объем выборки нужен?" В математической статистике есть методы определения необходимого объема выборки. Они основаны на разных подходах. Либо на задании необходимой точности оценивания параметров. Либо на явной формулировке альтернативных гипотез, между которыми необходимо сделать выбор. Либо на учете погрешностей измерений (методы статистики интервальных данных, см. ниже). Ни один из этих подходов нельзя применить в рассматриваемом случае.
Биномиальная модель выборки. Она применяется для описания ответов на закрытые вопросы, имеющие две подсказки, например, "да" и "нет". Конечно, пары подсказок могут быть иными. Например, "согласен" и "не согласен". Или при опросе потребителей кондитерских товаров первая подсказка может иметь такой вид: "Больше люблю "Марс", чем "Сникерс". А вторая тогда такова: "Больше люблю "Сникерс", чем "Марс".
Пусть объем выборки равен n. Тогда ответы опрашиваемых можно представить как X1 , X2 ,…,Xn , где Xi = 1, если i-й респондент выбрал первую подсказку, и Xi = 0, если i-й респондент выбрал вторую подсказку, i=1,2,…,n. В вероятностной модели предполагается, что случайные величины X1 , X2 ,…,Xn независимы и одинаково распределены. Поскольку эти случайные величины принимают два значения, то ситуация описывается одним параметром р - долей выбирающих первую подсказку во всей генеральной совокупности. Тогда
Р(Xi = 1) = р, Р(Xi = 0)= 1-р, i=1,2,…,n.
Пусть m = X1 + X2 +…+Xn . Оценкой вероятности р является частота р*=m/n. При этом математическое ожидание М(р*) и дисперсия D(p*) имеют вид
М(р*) = р, D(p*)= p(1-p)/n.
По Закону Больших Чисел (ЗБЧ) теории вероятностей (в данном случае - про теореме Бернулли) частота р* сходится (т.е. безгранично приближается) к вероятности р при росте объема выборки. Это и означает, что оценивание проводится тем точнее, чем больше объем выборки. Точность оценивания можно указать. Займемся этим.
По теореме Муавра-Лапласа теории вероятностей
![]()
где
![]() - функция стандартного
нормального распределения с математическим ожиданием 0 и дисперсией 1,
- функция стандартного
нормального распределения с математическим ожиданием 0 и дисперсией 1,
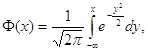
где
![]() = 3,1415925…-отношение
длины окружности к ее диаметру, e=
2,718281828… - основание натуральных логарифмов. График плотности стандартного
нормального распределения
= 3,1415925…-отношение
длины окружности к ее диаметру, e=
2,718281828… - основание натуральных логарифмов. График плотности стандартного
нормального распределения
![]()
очень точно изображен на германской денежной банкноте в 10 немецких марок. Эта банкнота посвящена великому немецкому математику Карлу Гауссу (1777-1855), среди основных работ которого есть относящиеся к нормальному распределению. В настоящее время нет необходимости вычислять функцию стандартного нормального распределения и ее плотность по приведенным выше формулам, поскольку давно составлены подробные таблицы (см., например, [3]), а распространенные программные продукты содержат алгоритмы нахождения этих функций.
С помощью теоремы Муавра-Лапласа могут быть построены доверительные интервалы для неизвестной эконометрику вероятности. Сначала заметим, что из этой теоремы непосредственно следует, что
![]()
Поскольку
функция стандартного нормального распределения симметрична относительно 0, т.е.
![]() то
то ![]()
Зададим
доверительную вероятность ![]() . Пусть
. Пусть ![]() удовлетворяет условию
удовлетворяет условию
![]()
т.е.
![]()
Из последнего предельного соотношения следует, что
![]()
К сожалению, это соотношение нельзя непосредственно использовать для доверительного оценивания, поскольку верхняя и нижняя границы зависят от неизвестной вероятности. Однако с помощью метода наследования сходимости [4, п.2.4] можно доказать, что
Следовательно, нижняя доверительная граница имеет вид
![]()
в то время как верхняя доверительная граница такова:
![]()
Наиболее
распространенным (в прикладных исследованиях) значением доверительной
вероятности является ![]() Иногда
употребляют термин "95% доверительный интервал". Тогда
Иногда
употребляют термин "95% доверительный интервал". Тогда ![]()
Пример.
Пусть n=500, m=200.
Тогда p*
=0,40. Найдем доверительный интервал для ![]()
![]()
Таким образом, хотя в достаточно большой выборке 40% респондентов говорят "да", можно утверждать лишь, что во всей генеральной совокупности таких от 35,7% до 44,3% - крайние значения отличаются на 8,6%.
Замечание. С достаточной для практики точностью можно заменить 1,96 на 2.
Удобные для использования в практической работе маркетолога и социолога таблицы точности оценивания разработаны во ВЦИОМ (Всероссийском центре по изучению общественного мнения). Приведем здесь несколько модифицированный вариант одной из них.
Табл.5. Допустимая величина ошибки выборки (в процентах)
|
Объем группы Доля р* |
1000 | 750 | 600 | 400 | 200 | 100 |
| Около 10% или 90% | 2 | 3 | 3 | 4 | 5 | 7 |
| Около 20% или 80% | 3 | 4 | 4 | 5 | 7 | 9 |
| Около 30% или 70% | 4 | 4 | 4 | 6 | 9 | 10 |
| Около 40% или 60% | 4 | 4 | 5 | 6 | 8 | 11 |
| Около 50% | 4 | 4 | 5 | 6 | 8 | 11 |
В
условиях рассмотренного выше примера надо взять вторую снизу строку. Объема
выборки 500 нет в таблице, но есть объемы 400 и 600, которым соответствуют ошибки
в 6% и 5% соответственно. Следовательно, в условиях примера целесообразно
оценить ошибку как ((5+6)/2)% = 5,5%. Эта величина несколько больше, чем
рассчитанная выше (4,3%). С чем связано это различие? Дело в том, что таблица
ВЦИОМ связана не с доверительной вероятностью ![]() а
с доверительной вероятностью
а
с доверительной вероятностью ![]() которой
соответствует множитель
которой
соответствует множитель ![]() Расчет
ошибки по приведенным выше формулам дает 5,65%, что практически совпадает со
значением, найденным по табл.5.
Расчет
ошибки по приведенным выше формулам дает 5,65%, что практически совпадает со
значением, найденным по табл.5.
Минимальный из обычно используемых объемов выборки n в маркетинговых или социологических исследованиях - 100, максимальный - до 5000 (обычно в исследованиях, охватывающих ряд регионов страны, т.е. фактически разбивающихся на ряд отдельных исследований - как в ряде исследований ВЦИОМ). По данным Института социологии Российской академии наук [5], среднее число анкет в социологическом исследовании не превышает 700. Поскольку стоимость исследования растет по крайней мере как линейная функция объема выборки, а точность повышается как квадратный корень из этого объема, то верхняя граница объема выборки определяется обычно из экономических соображений. Объемы пилотных исследований (т.е. проводящихся впервые, предварительно или как первые в сериях подобных) обычно ниже, чем объемы исследований по обкатанной программе.
Нижняя граница определяется тем, что в минимальной по численности анализируемой подгруппе должно быть несколько десятков человек (не менее 30), поскольку по ответам попавших в эту подгруппу необходимо сделать обоснованные заключения о предпочтениях соответствующей подгруппы в совокупности всех потребителей растворимого кофе. Учитывая деление опрашиваемых на продавцов и покупателей, на мужчин и женщин, на четыре градации по возрасту и восемь - по роду занятий, наличие 5 - 6 подсказок во многих вопросах, приходим к выводу о том, что в рассматриваемом проекте объем выборки должен быть не менее 400 - 500. Вместе с тем существенное превышение этого объема нецелесообразно, поскольку исследование является пилотным.
Поэтому объем выборки был выбран равным 500. Анализ полученных результатов (см. ниже) позволяет утверждать, что в соответствии с целями исследования выборку следует считать репрезентативной.
Организация опроса. Интервьерами работали молодые люди – студенты первого курса экономико-математического факультета Московского государственного института электроники и математики (технического университета) и лицея No.1140, проходившие обучение по экономике, всего 40 человек, имеющих специальную подготовку по изучению рынка и проведению маркетинговых опросов потребителей и продавцов (в объеме 8 часов). Опрос продавцов проводился на рынках г. Москвы, действующих в Лужниках, у Киевского вокзала и в других местах. Опрос покупателей проводился на рынках, в магазинах, на улицах около киосков и ларьков, а также в домашней и служебной обстановке.
Большое внимание уделялось качеству заполнения анкет. Интервьюеры были разбиты на шесть бригад, бригадиры персонально отвечали за качество заполнения анкет. Второй уровень контроля осуществляла специально созданная "группа организации опроса", третий происходил при вводе информации в базу данных. Каждая анкета заверена подписями интервьюера и бригадира, на ней указано место и время интервьюирования. Поэтому необходимо признать высокую достоверность собранных анкет.
Обработка данных. В соответствии с целью исследования основной метод первичной обработки данных - построение частотных таблиц для ответов на отдельные вопросы. Кроме того, проводилось сравнение различных групп потребителей и продавцов, выделенных по социально-демографическим данным, с помощью критериев проверки однородности выборок (см. ниже). При более углубленном анализе применялись различные методы статистики объектов нечисловой природы (более 90 % маркетинговых и социологических данных имеют нечисловую природу [6]). Использовались средства графического представления данных.
Итоги опроса. Итак, по заданию одной из торговых фирм были изучены предпочтения покупателей и мелкооптовых продавцов растворимого кофе. Совместно с представителями заказчика был составлен опросный лист (анкета типа социологической) из 16 основных вопросов и 4 дополнительных, посвященных социально-демографической информации. Опрос проводился в форме интервью с 500 покупателями и продавцами кофе. Места опроса - рынки, лотки, киоски, продуктовые и специализированные магазины. Другими словами, были охвачены все виды мест продаж кофе. Интервью проводили более 40 специально подготовленных (примерно по 8-часовой программе) студентов, разбитых на 7 бригад. После тщательной проверки бригадирами и группой обработки информация была введена в специально созданную базу данных. Затем проводилась разнообразная статистическая обработка, строились таблицы и диаграммы, проверялись статистические гипотезы и т.д. Заключительный этап - осмысление и интерпретация данных, подготовка итогового отчета и предложений для заказчиков.
Технология организации и проведения маркетинговых опросов лишь незначительно отличается от технологии социологических опросов, многократно описанной в литературе. Так, мы предпочли использовать полуоткрытые вопросы, в которых для опрашиваемого дан перечень подсказок, а при желании он может высказать свое мнение в свободной форме. Не уложившихся в подсказки оказалось около 5 % , их мнения были внесены в базу данных и анализировались дополнительно. Для повышения надежности опроса о наиболее важных с точки зрения маркетинга моментах спрашивалось в нескольких вопросах. Были вопросы - ловушки, с помощью которых контролировалась "осмысленность" заполнения анкеты. Например, в вопросе: "Что Вы цените в кофе: вкус, аромат, крепость, наличие пенки..." ловушкой является включение "крепости" - ясно, что крепость зависит не от кофе самого по себе, а от его количества в чашке. В ловушку никто из 500 не попался - никто не отметил "крепость". Этот факт свидетельствует о надежности выводов проведенного опроса. Мы считали нецелесообразным задавать вопрос об уровне доходов (поскольку в большинстве случаев отвечают "средний", что невозможно связать с определенной величиной). Вместо такого вопроса мы спрашивали: "Как часто Вы покупаете кофе: по мере надобности или по возможности?". Поскольку кофе не является дефицитным товаром, первый ответ свидетельствовал о наличии достаточных денежных средств, второй - об их ограниченности (потребитель не всегда имел возможность позволить себе купить банку растворимого кофе).
Стоимость подобных исследований - 5-10 долларов США на одного обследованного. При этом трудоемкость (и стоимость) начальной стадии - подготовки анкеты и интервьюеров, пробный опрос и др. - 30 % от стоимости исследования, стоимость непосредственно опроса - тоже 30 %, ввод информации в компьютер и проведение расчетов, построение таблиц и графиков - 20 %, интерпретация результатов, подготовка итогового отчета и предложений для заказчиков - 20 % . Таким образом, стоимость собственно опроса в два с лишним раза меньше стоимости остальных стадий исследования. И в выполнении работы участвуют различные специалисты. На первой стадии – в основном нужны высококвалифицированные аналитики. На второй – многочисленные интервьюеры, в роли которых могут выступать студенты и школьники, прошедшие конкретный курс обучения в 8-10 часов. На третьей – работа с компьютером (надо уметь строить и обсчитывать электронные таблицы или базы данных, использовать статистические пакеты, составлять и печатать таблицы и диаграммы и т.п.). На четвертой – опять в основном нужны высококвалифицированные аналитики.
Приведем некоторые из полученных результатов.
а) В отличие от западных потребителей, отечественные не отдавали предпочтения стеклянным банкам по сравнению с жестяными. Поскольку жестяные банки дешевле стеклянных, то можно было порекомендовать (в 1994 г., когда проходил опрос) с целью снижения расходов закупку кофе в жестяных банках.
б) Отечественные потребители готовы платить на 10-20% больше за экологически безопасный кофе более высокого качества, имеющий сертификат Минздрава и символ экологической безопасности на упаковке.
в) Средний объем потребления растворимого кофе - 850 г в месяц (на семью потребителя).
г) Потребители растворимого кофе делятся на классы. Есть "продвинутые" потребители, обращающие большое внимание на качество и экологическую безопасность, марку и страну производства, терпимо относящиеся к изменению цены. Эти "тонкие ценители" - в основном женщины от 30 до 50 лет, служащие, менеджеры, научные работники, преподаватели, врачи (т.е. лица с высшим образованием), пьющие кофе как дома, так и на работе, причем "кофейный ритуал" зачастую входит в процедуру деловых переговоров или совещаний. Противоположный по потребительскому поведению класс состоит из мужчин двух крайних возрастных групп - школьников и пенсионеров. Для них важна только цена, что очевидным образом объясняется недостатком денег.
Результаты были использованы заказчиком в рекламной кампании. В частности, обращалось внимание на сертификат Минздрава и на экологическую безопасность упаковки.
Приведем пример еще одной анкеты из нашего опыта, предназначенной для изучения спроса на образовательные услуги (табл.6).
Табл.6. Исследование рынка образовательных услуг
_____________________________________________________________
ИССЛЕДОВАНИЕ РЫНКА ОБРАЗОВАТЕЛЬНЫХ УСЛУГ
Анкета студентов первого курса экономико-математического факультета МГИЭМ(ту).
А. Объективные данные
1. Группа
2. Пол
3. Год рождения
4. Женат (замужем) - да/нет
Б. Общее изучение рынка
5. Почему Вы выбрали специальность экономиста?
6. Почему Вы выбрали именно МГИЭМ(ту) среди всех вузов Москвы, готовящих экономистов?
7. Как Вы представляете себе будущую деятельность по окончании МГИЭМ(ту)?
8. Есть ли у Вас надежда на то, что приобретаемые сейчас знания окажутся полезными в практической работе? Если нет, то зачем Вы учитесь?
В. Отношение к платному образованию
9. Если бы обучение в МГИЭМ(ту) было платным (порядка 1 миллиона руб. в год в ценах февраля 1994 г.), стали бы Вы поступать в МГИЭМ(ту)?
10. Если обучение в МГИЭМ(ту) станет платным, то останетесь ли Вы учиться в МГИЭМ(ту)? (Например, организация оплаты за учебу такова: некоторая фирма заключает контракт со студентом и оплачивает его учебу; студент самостоятельно ищет такую фирму.)
11. Представляет ли для Вас интерес возможность параллельно с дипломом МГИЭМ(ту) получить диплом бакалавра Межкультурного открытого университета (штаб-квартира в Нидерландах) по специальности "бизнес администрейшн" (обучение заочное, стоимость 1780 долларов США за курс)?
Г. О курсе "Основы экономики"
12. Нужно ли рассказывать содержание реферата-дайджеста учебника К. Макконнелла и С. Брю "Экономикс: Принципы, проблемы и политика" или считать его общеизвестным и говорить о том, чего в нём нет?
13. Полезен ли электронный учебник? Если нет, то почему?
14. Нужны ли Вам индивидуальные занятия в аудитории (а не в компьютерном классе с электронным учебником) и в каком виде?
15. Какие темы Вы считаете полезным рассмотреть дополнительно?
16. Сформулируйте иные Ваши замечания и предложения по курсу "Основы экономики": по лекциям, практическим и индивидуальным занятиям.
Д. Дополнительная информация
17. Какие предметы обучения - самые трудные, какие - самые легкие на первом семестре?
18. Подрабатываете ли Вы? Если согласны, укажите примерную (среднюю) сумму в месяц.
19. Существенна ли для Вас стипендия?
20. Есть ли у Вас дома компьютер?
21. Участвуете ли Вы в каких-либо политических движениях, партиях? Если согласны, назовите.
Проверка однородности двух биномиальных выборок
Как сравнить две группы - мужчин и женщин, молодых и пожилых, и т.п.? В маркетинге это важно для сегментации рынка. Если две группы не отличаются по ответам, значит, их можно объединить в один сегмент и проводить по отношению к ним одну и ту же маркетинговую политику, в частности, осуществлять одни и те же рекламные воздействия. Если же две группы различаются, то и относиться к ним надо по-разному. Это - представители двух разных сегментов рынка, требующих разного подхода при борьбе за их завоевание.
Эконометрическая постановка такова. Рассматривается вопрос с двумя возможными ответами, например, "да" и "нет". В первой группе из n1 опрошенных m1 человек сказали "да", а во второй группе из n2 опрошенных m2 сказали "да". В вероятностной модели предполагается, что m1 и m2 - биномиальные случайные величины B(n1 , p1 ) и B(n2 , p2 ) соответственно. (Запись B(n , p) означает, что случайная величина m, имеющая биномиальное распределение B(n , p) с параметрами n - объем выборки и p - вероятность определенного ответа (скажем, ответа "да"), может быть представлена в виде m = X1 + X2 +…+Xn , где случайные величины X1 , X2 ,…,Xn независимы, одинаково распределены, принимают два значения1 и 0, причем Р(Xi = 1) = р, Р(Xi = 0)= 1-р, i=1,2,…,n.)
Однородность двух групп означает, что соответствующие им вероятности равны, неоднородность - что эти вероятности отличаются. В терминах математической статистики: необходимо проверить гипотезу однородности
H0 : p1 = p2
при альтернативной гипотезе
H1 : p1 ![]() p2 .
p2 .
(Иногда представляют
интерес односторонние альтернативные гипотезы ![]() и
и
![]() .)
.)
Оценкой вероятности р1 является частота р1*=m1/n1, а оценкой вероятности р2 является частота р2*=m2/n2 . Даже при совпадении вероятностей р1 и р2 частоты, как правило, различаются, как говорят, "по чисто случайным причинам". Рассмотрим случайную величину р1* - р2*. Тогда
M(р1* - р2*) = р1 - р2 , D(р1* - р2*) = р1 (1 - р1 )/ n1 + р2 (1-р2 )/ n2 .
Из теоремы Муавра-Лапласа и теоремы о наследовании сходимости [4, п.2.4] следует, что
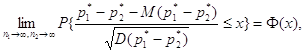
где ![]() - функция стандартного
нормального распределения с математическим ожиданием 0 и дисперсией 1. Для
практического применения этого соотношения следует заменить неизвестную
эконометрику дисперсию разности частот на оценку этой дисперсии:
- функция стандартного
нормального распределения с математическим ожиданием 0 и дисперсией 1. Для
практического применения этого соотношения следует заменить неизвестную
эконометрику дисперсию разности частот на оценку этой дисперсии:
D*(р1* - р2*) = р*1 (1 - р*1 )/ n1 + р*2 (1-р*2 )/ n2 .
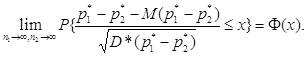 |
С помощью указанной выше математической техники можно показать, что
При справедливости гипотезы однородности M(р1* - р2*) = 0. Поэтому правило принятия решения при проверке однородности двух выборок выглядит так:
1. Вычислить статистику
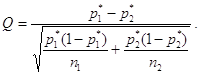
2. Сравнить значение модуля статистика |Q| с граничным значением K. Если |Q|<K, то принять гипотезу однородности H0 . Если же |Q|>K, то заявить об отсутствии однородности и принять альтернативную гипотезу H1 .
Граничное значение К
определяется выбором уровня значимости статистического критерия проверки
однородности. Из приведенных выше предельных соотношений следует, что при
справедливости гипотезы однородности H0 для уровня значимости ![]() имеем (при
имеем (при ![]()
![]()
Следовательно, граничное значение в зависимости от уровня значимости целесообразно выбирать из условия
![]()
Здесь ![]() - функция, обратная к
функции стандартного нормального распределения. В социально-экономических
исследованиях наиболее распространен 5% уровень значимости, т.е.
- функция, обратная к
функции стандартного нормального распределения. В социально-экономических
исследованиях наиболее распространен 5% уровень значимости, т.е. ![]() Для него К = 1,96.
Для него К = 1,96.
Пример. Пусть в первой группе из 500 опрошенных ответили "да" 200, а во второй группе из 700 опрошенных сказали "да" 350. Есть ли разница между генеральными совокупностями, представленными этими двумя группами, по доле отвечающих "да"?
Уберем из формулировки примера термин "генеральная совокупность".
Пусть из 500 опрошенных мужчин ответили "да, я люблю пепси-колу" 200, а из 700 опрошенных женщин 350 сказали "да, я люблю пепси-колу". Есть ли разница между мужчинами и женщинами по доле отвечающих "да" на вопрос о любви к пепси-коле?
В рассматриваемом примере
нужные для расчетов величины таковы: ![]() Вычислим
статистику
Вычислим
статистику
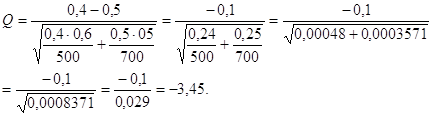
Поскольку |Q| = 3,45 > 1,96, то необходимо отклонить нулевую гипотезу т принять альтернативную. Таким образом, мужчины и женщины отличаются по рассматриваемому признаку - любви к пепси-коле.
Необходимо отметить, что результат проверки гипотезы однородности зависит не только от частот, но и от объемов выборок. Предположим, что частоты (доли) зафиксированы, а объемы выборок растут. Тогда числитель статистики Q не меняется, а знаменатель уменьшается, значит, вся дробь возрастает. Поскольку знаменатель стремится к 0, то дробь возрастает до бесконечности и рано или поздно превзойдет любую границу. Есть только одно исключение - когда в числителе стоит 0. Следовательно, вывод эконометрика должен выглядеть так: "различие обнаружено" или "различие не обнаружено". Во втором случае различие, возможно, было бы обнаружено при увеличении объемов выборок.
Как и для доверительного оценивания вероятности, во ВЦИОМ разработаны две полезные таблицы, позволяющие оценить вызванные чисто случайными причинами допустимые расхождения между частотами в группах. Эти таблицы рассчитаны при выполнении нулевой гипотезы однородности и соответствуют ситуациям, когда частоты близки к 50% (табл.7) или к 20% (табл.8). Если наблюдаемые частоты - от 30% до 70%, то рекомендуется пользоваться первой из этих таблиц, если от 10% до 30% или от 70% до 90% - то второй. Если наблюдаемые частоты меньше 10% или больше 90%, то теорема Муавра-Лапласа и основанные на ней асимптотические формулы дают не очень хорошие приближения, целесообразно применять иные, более продвинутые математические средства, в частности, приближения с помощью распределения Пуассона.
Табл.7.
Допустимые расхождения (в %) между частотами в двух группах в случае, когда наблюдаются частоты от 30% до 70%
|
Объемы Групп |
750 | 600 | 400 | 200 | 100 |
| 750 | 6 | 7 | 7 | 10 | 12 |
| 600 | 7 | 8 | 8 | 11 | 13 |
| 400 | 7 | 8 | 10 | 11 | 14 |
| 200 | 10 | 11 | 11 | 13 | 16 |
| 100 | 12 | 13 | 14 | 16 | 18 |
Табл.8.
Допустимые расхождения (в %) между частотами в двух группах в случае, когда наблюдаются частоты от 10% до30% или от 70% до 90%
|
Объемы Групп |
750 | 600 | 400 | 200 | 100 |
| 750 | 5 | 5 | 6 | 8 | 10 |
| 600 | 5 | 6 | 7 | 8 | 10 |
| 400 | 6 | 7 | 8 | 9 | 11 |
| 200 | 8 | 8 | 9 | 10 | 12 |
| 100 | 10 | 10 | 11 | 12 | 14 |
В условиях разобранного выше примера табл.7 дает допустимое расхождение 7%. Действительно, объем первой группы 500 отсутствует в таблице, но строки, соответствующие объемам 400и 600, совпадают для первых двух столбцов слева. Эти столбцы соответствуют объемам второй группы 750 и 600, между которыми расположен объем 700, данный в примере. Он ближе к 750, поэтому берем величину расхождения, стоящую на пересечении первого столбца и второй (и третьей) строк, т.е. 7%. Поскольку реальное расхождение (10%) больше, чем 7%, то делаем вывод о наличии значимого различия между группами. Естественно, этот вывод совпадает с полученным ранее расчетным путем.
Допустимое расхождение ![]() между частотами нетрудно
получить расчетным путем. Для этого достаточно воспользоваться формулой для
статистики Q и определить, при каком максимальном
расхождении частот все еще делается вывод о том, что верна гипотеза
однородности. Следовательно, допустимое
расхождение
между частотами нетрудно
получить расчетным путем. Для этого достаточно воспользоваться формулой для
статистики Q и определить, при каком максимальном
расхождении частот все еще делается вывод о том, что верна гипотеза
однородности. Следовательно, допустимое
расхождение ![]() находится из уравнения
находится из уравнения
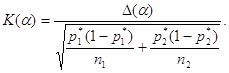
Таким образом,
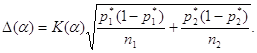
Для данных примера ![]() = 1,96
= 1,96 ![]() 0,029 = 0,057, или 5,7%,
для уровня значимости 0,05. .
0,029 = 0,057, или 5,7%,
для уровня значимости 0,05. .
Для других уровней
значимости надо использовать другие коэффициенты ![]() Так, K(0,01) = 2,58 для уровня
значимости 1% и K(0,10) = 1,64 для уровня значимости 10%. Для данных примера
Так, K(0,01) = 2,58 для уровня
значимости 1% и K(0,10) = 1,64 для уровня значимости 10%. Для данных примера ![]() = 2,58
= 2,58 ![]() 0,029 = = 0,7482
0,029 = = 0,7482 ![]() 0,075, или 7,5%, для
уровня значимости 0,01. Если округлить до ближайшего целого числа процентов, то
получим 7%, как при использовании таблицы 7 выше.
0,075, или 7,5%, для
уровня значимости 0,01. Если округлить до ближайшего целого числа процентов, то
получим 7%, как при использовании таблицы 7 выше.
Анализ таблиц 7 и 8 показывает, что для констатации различия частоты должны отличаться не менее чем на 6%, а при некоторых объемах выборок - более чем на 10%, при объемах выборок 100 и 100 - на 19%. Если частоты отличаются на 5% или менее, можно сразу сказать, что эконометрический анализ приведет к выводу о том, что различие не обнаружено (для выборок объемов не более 750).
В связи с этим возникает вопрос: каково типовое отличие частот в двух выборках из одной и той же совокупности? Разность частот в этом случае имеет нулевое математическое ожидание и дисперсию
![]()
Величина р(1-р) достигает максимума при р=1/2, и этот максимум равен 1/4. Если р=1/2, а объемы двух выборок совпадают и равны 500, то дисперсия разности частот равна
![]()
Следовательно, среднее
квадратического отклонение ![]() равно
0,032, или 3,2%. Поскольку для стандартной нормальной случайной величины в 50%
случаев ее значение не превосходит по модулю 0,67 (а в 50% случаев - больше
0,67), то типовой разброс равен 0,67
равно
0,032, или 3,2%. Поскольку для стандартной нормальной случайной величины в 50%
случаев ее значение не превосходит по модулю 0,67 (а в 50% случаев - больше
0,67), то типовой разброс равен 0,67![]() , а в
рассматриваемом случае- 2,1%. Приведенные соображения дают метод контроля за
правильностью проведения повторных опросов. Если частоты излишне устойчивы, это
подозрительно!
, а в
рассматриваемом случае- 2,1%. Приведенные соображения дают метод контроля за
правильностью проведения повторных опросов. Если частоты излишне устойчивы, это
подозрительно!
Литература
1. Сэндидж Ч., Фрайбургер В., Ротцолл К. Реклама: теория и практика: Пер. с англ. - М.: Прогресс, 1989. - 630 с.
2. Ядов В.А. Стратегии и методы качественного анализа данных. - Журнал "Социология: методология, методы, математические модели", 1991, No.1, с.14-31.
3. Большев Л.Н., Смирнов Н.В. Таблицы математической статистики. - М.: Наука, 1983. - - 416 с.
4. Орлов А.И. Устойчивость в социально-экономических моделях. - М.: Наука, 1979. - 296 с.
5. Опыт применения ЭВМ в социологических исследованиях. - М.: Институт социологических исследований АН СССР, Советская социологическая ассоциация, 1977. - 158 с.
6. Орлов А.И. Общий взгляд на статистику объектов нечисловой природы. - В сб.: Анализ нечисловой информации в социологических исследованиях (научные редакторы: В.Г. Андреенков, А.И.Орлов, Ю.Н.Толстова). - М.: Наука, 1985. // С.58-92.